Table des matières
2022/01/09 (infra)
Présences :
- HgO
- wget
- tharyrok
- célo
Excusé·e·s :
- Julie
Météo
Moment informel durant lequel on exprime en peu de mots comment on se sent et si on a une attente forte pour la réunion.
Ce n'est pas un moment de discussion mais d'expression individuelle et ce n'est pas obligatoire 
Attente(s) forte(s)
Si l'une ou l'autre personne exprime une attente forte, merci de vous en occuper en priorité ou de la noter dans le hub ou dans un point approprié.
Fin vers 16H / avant 19h
Neutriton
Retour sur les différents Neutriton et des décisions prises/à prendre https://wiki.neutrinet.be/fr/infra/start#reunions
Pour chaque Neutriton, on traitait un sujet technique dans le but d'avoir des solutions techniques pour Neutrinet.
PFSense
Pour utiliser CARP avec proxmox il faut une interface physique par vlan pour avoir une adresse mac par vlan.
Actuellement, des soucis avec edge-[01,02] et pfsense-[01,02] car edge-02 répond sur l'ip vip même s'il est en slave. pfsense-02 est éteint.
Pour que la HA fonctionne, il faut attendre la refonte des réseaux (cf. plus bas).
wget: dispose d'une version Entreprise de OPNsense avec des heures de consultances.
À l'époque, il y avait des instabilités avec OPNsense, mais elles ont été résolues depuis, normalement.
Il n'y avait pas non plus de séparation claire entre les groupes de règle.
Configuration management
Nous avons choisi ansible et le repos est ici : https://gitlab.domainepublic.net/Neutrinet/infra/
Parmi les raisons :
- sans agent
- code déjà existant
- compatible avec git
Les secrets sont dans le password store de Neutrinet, lui aussi sur un repo git.
HgO et Tharyrok ont écrit des playbooks Ansible en 2021 pour compléter les besoins de l'infra et mettre en pratique les décisions des Neutriton.
Pour contribuer, on peut relire des merge request ou en proposer, ou encore ouvrir des tickets.
Il y a aussi encore beaucoup de documentation à faire. Ce n'est pas forcément très technique et c'est quelque chose qu'on peut faire ensemble.
TODO : Reunion sur les belles et bonnes pratiques Ansible
Reverse proxy
Choix de haproxy comme frontend et caddy2 pour les backend.
Quand c'est possible, on privilégie haproxy, et s'il faut servir du PHP ou des pages statiques, on utilise caddy2.
wget: quid du point d'entrée si plusieurs DC. → La question ne se pose pas car un seul DC pour l'instant.
PostgreSQL HA
Choix de patroni.
L'idée était de mutualiser la base de données PostgreSQL avec tous les services de Neutrinet. Pour ce faire, on a choisi Patroni pour avoir un cluster en HA.
Monitoring
Utilisation de telegraf, prometheus, altermanager, grafana, Loki.
- Telegraf comme sonde (récupére les metrics sur la machine)
- Prometheus : rassemble les metrics de toutes les machines
- Alertmanager : pour envoyer les alertes
- Grafana : pour visualiser les métriques et les logs
- Loki : pour les logs.
Pour le moment, on a telegraf, prometheus et altermanager. Il reste encore Loki à mettre en place, et on a un soucis sur la rétention long terme des metrics Prometheus.
Backup
Choix a définir entre borgbackup et restic.
SSO
On a choisi Keycloak.
Permet d'avoir un identifiant unique dans tout Neutrinet.
Pour le moment, ça n'est pas encore mis en place.
wget: intéressé de suivre ce projet, mais la lecture de la pull request répond à la question. tharyrok: faire un neutriton en reviewant une merge request et en regardant comment c'est configuré.
TODO: Neutriton pour review la merge request et regarder comment on configure Keycloak.
DDOS
On a choisi FastNetMON.
Permet de mitiger les attaques DDoS. Suite à ce Neutriton, Verixi nous a contacté pour nous donner quelques astuces pour mitiger les DDoS.
Structure des services et VM
Avant tous les services étaient sur la meme machine, on a séparé ça avec une VM par service.
Reste à déplacer Mattermost et l'admin de ISPng (frontend statique). Et bien entendu, ISPng lui-même.
Ce qui reste
- Sécurité
-
- CrowdSec: L7 DDoS applicatif, alors que FastNetMon L3 DDoS IP. Ils sont complémentaires.
- Analyse des logs applicatifs (derrière un caddy par ex)
- Permet différents types de ban (captcha, blacklist ip, …)
- Prise de décision distribuée entre les machines
- Détection physique… est-ce qu'on retire un disque dur ? est-ce qu'on en branche un ?
-
- Chiffrement
- Est-ce qu'on veut chiffrer les disques-dur ? Comment on le fait ? À quel niveau ?
- Série d'articles pour le blog en préparation (complexité (démarrage notamment), aspects juridiques et légaux, etc)
- Ateliers / cours sur les outils
- Faire en sorte que tout le monde dans le hub infra maîtrise les outils qui ont été mis en place
- Ex: git, gpg, ssh, ansible, keycloak, pfsense, etc.
Finance
| Host | Lieux | CPU | RAM | Disk | Cout/mois | Periodicité | Rôle |
| probe-01 | FirstHeberg | 2 | 1G | 20G | 0 € | neant | peering verixi |
| probe-02 | OVH | 1 | 2G | 20G | 3.63 € | annuel | peering belgiumix / bnix |
| monitoring | Hetzner | 2 | 4G | 40G | 7.2 € | mensuel | transit verixi |
| storage box | Hetzner | N/A | N/A | 500G | 5.93 € | mensuel | storage monitoring |
| runner | Hetzner | 1 | 2G | 20G | 4.21 € | mensuel | Gitlab runner |
| Hetzner | 2 | 8G | 80G | 13 € | mensuel | serveur SMTP | |
| pbs | Hetzner | 8T 3,80 GHz | 32G | 4x2T | 58 € | mensuel | Proxmox Backup |
| Total | 91.97 € | mensuel |
- FirstHeberge (gratuit) : 2 Vcore, 1Go Ram, 20 Go Disque
- OvhCloud (43,56 € /ans, renouvellement mai 2022) : 1 Vcore, 2Go ram, 20 Go Disque
- Hetzner CX21 (7,20 € / mois, avec option backup) : 2Vcore, 4 Go Ram, 40 Go Disque local + StorageBox 20 (5,93 € / mois) : 500 Go Disque
- Hetzner CX11 (4,21 € / mois) :1 Vcore, 2 Go Ram, 20 Go Disque local
- Hetzner CX31 (13 € / mois, avec option backup) : 2Vcore, 8 Go Ram, 80 Go Disque local
- Hetzner SB57 (58€ / mois) : Intel Xeon E3-1245V2, 32Go de ram, 4*2 To disque
Pour économiser, on pourrait déplacer runner et mail assez facilement pour les mettre dans LouiseDC.
Infrastructure
Listons les tâches à faire, service à améliorer.
Les backups
Choix entre restic et borg ?
Petit rappel, les deux outils sont assez similaire (déduplication, etc.).
Différence :
- restic utilise comme backend de quoi backuper directement sur du S3, du samba, du drive Microsoft… Borg ne backup que sur du ssh ou en local.
- restic est consommateur de ram et d'espace comparé à borg.
- restic est plus récent que borg
Borg est un outil que plusieurs d'entre nous ont utilisé. Restic moins, donc c'est peut-etre mieux de commencer avec borg. Par ex: https://wiki.gnuragist.es/documentation:borg
Le jour ou on change, ça se fait facilement. On perdra la rétention mais on peut garder les anciens backup.
Décision : Utiliser Borg (borgmatic) soit avec une storage box, soit sur une machine avec beaucoup d'espace disque.
Pour le S3, le mieux pour le backuper est d'avoir un clone en utilisant rclone vers un autre service compatible S3.
Choix à faire pour les bases de données:
- PgBackRest
- Barman
- Wal-e / Wal-g
- Autre ?
TODO: Faire une demo de ces outils et choisir a la prochaine réunion. On active les dump avec borgmatic
Choix des lieux pour les backups + budget
Est-ce que la storage box se trouve dans le même DC que le serveur utilisé pour les backups Proxmox (PBS) ?
- Storage box : Helsinki (Finlande), et Francfort pour la VM monitoring
- PBS : Francfort
On peut aussi utiliser le Cold Storage s3 de Scaleway : https://www.scaleway.com/fr/c14-cold-storage/
Décision : Faire un backup toutes les semaines dans un nouveau bucket, et en conservé 52 (1 an). Par exemple, pour 50Go de backup, ça revient à 5.2€ / an.
Mattermost board
https://docs.mattermost.com/guides/boards.html
Pour avoir une meilleure vue des tâches à faire dans le hub infra, et permettre plus facilement aux nouveaux venus de participer.
Gitlab serait toujours utilisé pour la gestion au niveau du code (Ansible, Neutrinet app, etc.), et Mattermost board serait pour la gestion quotidienne.
Monitoring
Durée de rétention des données (promscale)
Sur la VM monitoring, il y a une storage box pour accueillir les metrics de prometheus.
On voulait faire sur le mode fédération pour recueillir toutes les métriques, y compris avec coupure réseau.
Cependant, ce n'est pas comme ça que fonctionne la federation dans Prometheus.
En mode fédération c'est le prometheus principal qui va récupérer les données des prometheus distant. En mode remote c'est les prometehous locaux qui envoient les données au remote storage. On stocke en local et puis on envoit les métrics chez Hetzner. Du coup, en cas de coupure, cela se re-synchronise.
Il y a promscale qui propose cela. En combinant promscale et prometeus et postgresl on a le meilleur des mondes.
Tharyrok est en train de faire un POC avec une Kimsufi (21.76€/mois) et 4To de stockage comme alternative à la storage box.
À noter que cela pourrait être aussi un 3ème lieux pour les backups.
TODO:
- contacter domainepublic pour avoir un espace de backup
- poc promscale
Alerting
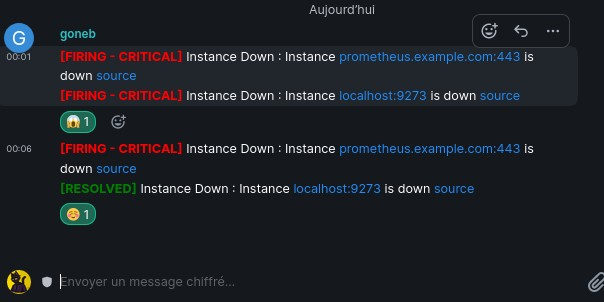
- Alertes via
- Matrix
- Signal
- SMS
- Quid des alertes emails ?
On utilise un bot maintenu par l'équipe de Matrix pour envoyer les alertes dans un salon matrix :
On utiliserait le matrix de domainepublic. Attention de ne pas créer une trop grande dépendance dans l'infra de domaine public.
On est favorable à arreter les adresses mails quand c'est mis en place.
Par contre, il manque un outil de gestion des alertes (acknowledgement, pagerduty, alerta, etc.) et d'escalation.
Solution de classer les alertes en fonction de la criticité, et envoyer un sms uniquement pour les trucs vraiment important.
Ordre de priorité d'implémentation
- matrix : en cours https://gitlab.domainepublic.net/Neutrinet/infra/-/merge_requests/138
- sms : to do
- signal: plus tard
Status Page
On avait parlé d'avoir une status page, un peu comme status.gnuragist.es (statping) ou via un autre outil (cachet, uptime kuma)
En travaillant sur le bot matrix, on se dit qu'on pourrait avoir un channel public avec des alertes assez simple (du style Mattermost est down, VPN est down, etc.), et cela permettrait aussi de discuter du problème sur ce cannal quand tout est cassé.
Mais peut-être que uptime-kuma permet aussi tout ça, donc à tester.
TODO : Exprimenter uptime-kuma et/ou salon public matrix
Ansible
Utilisation d'un agent comme Ansible Semaphore ?
Pour le projet ketupa, on a besoin de lancer des playbooks Ansible à intervalle régulier pour faire des modifications de config. C'est soit ça, soit avoir un autre outil de config management.
Autre problème, ansible-pull ne permet pas de se déclencher à distance, mais uniquement via ligne de commande. Par ex, via un cron job.
Semaphore date d'il y a quelques années mais intègre des fonctions intéressantes : api, pouvoir lancer des playbook sur tous les serveurs tous les jours ou tous les deux jours. Comme ça, si un humain modifie quelque chose, ça n'est pas persistent, ça oblige a passer par ansible (avec le risque que c'est plus exigent pour faire les playbook).
La gestion des vaults est un peu hacky mais ça marche bien.
Pourquoi on a besoin de ces fonctionement de ketupa, que ce soit provisionner un nouveau vpn ou une vm, il faut modifier une config… on préfère appliquer alors un playbook.
Semaphore serait cependant une vm qui aurait vue sur tout les réseaux, ou alors on limite sa vue avec du routing. Mais cette machine ne serait pas accessible de l'extérieur, mais uniquement en passant par les pfsense.
On pourrait aussi avoir besoin de semaphore pour déployer le nouveau vpn.
Pas d'objection forte pour tester.
Postfix vs Opensmtpd
Il y a deux cas d'utilisation :
- serveur smtp
- MTA pour toutes les VMs
- les applications envoient leur mail via localhost, et le MTA transfère vers la VM mail.
- permet d'avoir une queue lors de la perte d'internet
- permet d'avoir les statuts des cron job
Exemple opensmtpd en mta :
listen on localhost table aliases file:/etc/aliases table secrets file:/etc/smtpd-secret action "relay" relay host "tls+auth://label@example.com" auth <secrets> mail-from "toto@example.com" match for any action "relay"
VM a déplacer/créer
- Mattermost → vm mattermost
- ISPng admin → vm web-static
- Runner gitlab → vm runner
- Mail → vm mail → opensmtpd
- Zammad → vm zammad
- ISPng → mettre à jour vers buster (pas possible bullseye)
Passage de buster vers bullseye
OOB via 4G
Obé ? Obééé ?
Pano ? Non c'est Obé…
Out-of-band management : https://en.wikipedia.org/wiki/Out-of-band_management
Tharyrok a testé la 4G dans le datacenter, et en tout cas avec son smartphone et Orange, il avait du réseau.
https://www.thingsmobile.com/business/plans/individual-sim-card-data-packages Nous permettrait d'avoir une carte sim sur topi, et d'avoir un VPN fournit par thingsmobile.
On a droit à 1Go de traffic sur un an pour 50€/an. Cela permettrait de se connecter en ssh à topi quand tout est cassé. De manière à pouvoir réparer les edge.
On n'a pas le prix du VPN par contre.
Que ce passe-t-il quand topi n'est plus disponible ? Est-ce que c'est nécésaire ?
TODO : Reporté a la prochaine réunion
Version tracker
https://release-monitoring.org/
C'est un projet fedora qui permet de suivre les versions des projets.
Journée cabelporn
TODO: Créer un sondage pour fin janvier
Miam miam plus de ram
TODO: prochaine réunion
Refonte des réseaux

-
- Gestion des templates plus facile dans Bird
- Rechargement à chaud des config sans casser les sessions BGP en cours
- Filtre RPKI avec Routinator 3000 sur edge-01 & edge-02
- Les edges ne s'échangent plus leur full view.
- lorsqu'un paquet vient de belgiumix, il passe par edge-02 puis par edge-01 et enfin pfsense, ce qui n'est pas optimisé
- si un jour on a un edge-03, ce sera le bor*** pour gérer ça.
- les vm core & bra prennent les descisions de routage (à la place des edge)
- Core = cœur de réseau
- Bra = broadband access server (premier équipements ip qui viennent de la collecte)
- Désactivation du conntrack sur les liens réseaux de edge & core & bra
- Utilisation d'un VRF de management sur les vm edge & core & bra pour le monitoring, métrique de même qu'avoir une porte de secours
- core-01 & core-02 serviront de défaut route pour le réseau patata et les vm des amis (avec une ip VIP)
- core-03 & core-04 sont identiques aux autres core mais pour le réseau chez-mémé (VM et futur membre le la bai)
- bra-01 & bra-02 ils serviront de défaut route pour la collecte, on les appelle Broadband Access Server
- activation de sFlow sur les vm de réseaux dans l'intention de mettre FastNetMon
- Mise en place d'un site web uniquement sur comment fonctionne notre AS avec quelques outils agréable comme une Weathermap un Looking Glass pour aider les autres membres du réseau Internet de debug des bouts du réseau.
{kind=link}
La problématique est de pouvoir monter une vingtaine de sessions BGP. Et FRR ne garde pas l'ordre des règles, ce qui rend compliqué la notion d'idempotence nécessaire à Ansible.
Problème des PfSense qui répondent à la place de l'autre… et du coup les requêtes sont rejetées.
Questions :
- Est-ce qu'on change l'IP du VPN ? On la mettrait sur 80.67.181.129, parce que c'est utilisé comme default gateway sur les clients. Cela reviendrait à considérer que le VPN est un service réseau au même titre que la collecte, chez-meme, patata.
- Parce qu'actuellement, ça passe par pfSense, en rajoutant beaucoup de règle… alors qu'au final c'est quand meme géré par le firewall de la vm vpn… et qu'elle doit aussi communiquer en BGP avec les autres machines qui font du VPN.
- Voir combien de RAM ça va consommer avec bird. Actuellement, une double full view avec frr c'est 6Go… Bird a l'air de consommer moins mais à voir.
TODO: choisir une date pour appliquer la nouvelle config, en février
Chez-mémé
Chiffrer ou pas les disques des serveurs ? TODO : Apres le neutriton, qui sera donc après la refonte des réseaux
Mais il faudrait le faire avant qu'on mette nos vm… donc à faire plus ou moins dans le meme timing que la refonte du réseau. Si on le fait après, ce sera plus long mais pas impossible.
Collecte
Chiffrer la communication entre le TPE (microtik dans les ménages) et Neutrinet, ou pas ?
On peut faire la communication p2p (point to point) entre Neutrinet et le TPE avec ou sans chiffrement.
On utiliserait :
Sans chiffrement :
Avec chiffrement :
- OpenVPN
- WireGuard
TODO: La journée de la collecte
Ketupa
L'etat actuel de ketupa n'est pas exploitable et il ne faut pas compter dessus ni utiliser son code.
Le but initial est de remplacer ISPng, mais aussi backoffice pour les commandes de brique, car ces deux projets ne sont plus du tout maintenus.
Il y a aussi la question d'avoir un outil de commandes des VMs, etc. Bref, c'est le futur SI de Neutrinet.
TODO:
- faire un tour des hub pour savoir les besoins
- communiquer sur le besoin des developemements (channel mattermost, mailing list et réunion des membres)
Prochaine réunion
TODO: réunir les TODOs (ne pas oublier celui qui suit)
Prochaine réunion hub infra : réunion en mars
TODO: Après la refonte des réseaux, on se planifie la réunion hub-infra en mars
Lieu : Jitsi & Caldarium
Météo de fin
Moment informel durant lequel on exprime en peu de mots comment, à titre personnel, la réunion a été vécue que ce soit positif ou négatif. Si une ou plusieurs tension est née durant la réunion, il est peut-être nécessaire d'envisager l'une ou l'autre réunion pour y remédier.