Table des matières
2022/05/29 (infra)
Présences :
- Tharyrok
- HgO
- Célo
Météo
Moment informel durant lequel on exprime en peu de mots comment on se sent et si on a une attente forte pour la réunion.
Ce n'est pas un moment de discussion mais d'expression individuelle et ce n'est pas obligatoire ")
Attente(s) forte(s)
Hub service
Maintenance reinstallation
Proposition de transformer la journée keycloak prévue le 11 juin par une journée au LouiseDC.
On placerait le matériel qu'on a reçu, on réinstallerait et on appliquerait le chiffrement en même temps.
Proposition acceptée \o/
Backup
HgO est en train de faire les playbook ansible pour gérer Borg et borgmatic. Comme borgmatic permet d'avoir des sous-config, on va faire un fichier de config par application.
Concernant les backups de base de données, on va faire aussi les backups avec barman / pgbackrest et borgmatic.
Ca fait sens d'avoir les deux parce que l'un fait un dump et l'autre fait un backup WAL (Write-Ahead Logging : des logs sont écrit pour les transactions en cours, et s'il y a un crash, l'outil de backup pourra utiliser ces logs pour ne pas perdre de donnée).
Pour borgmatic, on va faire le backup au niveau de l'application, donc on se connectant aux haproxy pour parler au cluster postgresql.
TODO: Il faut faire un POC pour barman (+ démo).
https://wiki.neutrinet.be/fr/rapports/2022/01-09#les_backups https://wiki.neutrinet.be/fr/rapports/2021/09-05#backups
keycloak
Tharyrok est en train de préparer le playbook ansible pour keycloak. C'est assez bloquant pour mettre en place des outils web (ex: netbox). Le playbook est presque terminé.
Il reste à faire la personnalisation de l'interface d'inscription qui sera affichée aux utilisateurs.
L'utilisation sera facultative jusqu'à la journée keycloak puis deviendra obligatoire pour tout.
Il faudra réfléchir sur la découpe des royaumes (rien à voir avec les querelles communautaires belges) . 
VictoriaMetrics
https://victoriametrics.com/ (licence Apache2) https://docs.victoriametrics.com/
La solutioon Postgresql + TimescaleDB est abandonné car on est limité en stockage de métriques.
C'est un remplacement de Prometheus et Alertmanager.
C'est rétrocompatible avec prometheus, donc ce qu'on a fait peut être réutilisé, il faut juste légèrement changer la config.
Le plugin pour l'alerte matrix devrait aussi fonctionner.
Cela pourrait être bien de migrer sur Victora pour avoir les métriques à long terme. Il y a un gain de performance non négligeable (un ordre de grandeur).
Il y a aussi un plugin qui pourrait remplacer telegraf.
On peut aussi mettre en place de la HA, même si on ne va probablement pas aller aussi loin dans Neutrinet.
On peut installer la version communautaire, la version pro, c'est surtout du support qui est ajouté.
Cela intègre aussi un outil de backup pour dumper toutes les métriques dans un format compressible et les restaurer au besoin.
C'est aussi compatible InfluxDB, un autre format de métrics. Par exemple, Proxmox en produit, donc ça peut nous servir.
https://victoriametrics.com/blog/proxmox-monitoring-with-dbaas/
On peut choisir l'intervalle des metrics selon la longévité (1s pour la dernière heure, 1m pour les metrics d'un an) c'est peut être uniquement pour la version entreprise : https://docs.victoriametrics.com/Single-server-VictoriaMetrics.html#downsampling
La gestion des labels (relabeling) pour les metrics se fait dans une configuration à part : https://docs.victoriametrics.com/Single-server-VictoriaMetrics.html#relabeling
TODO: Créer un playbook ansible pour VictoriaMetrics
Probe
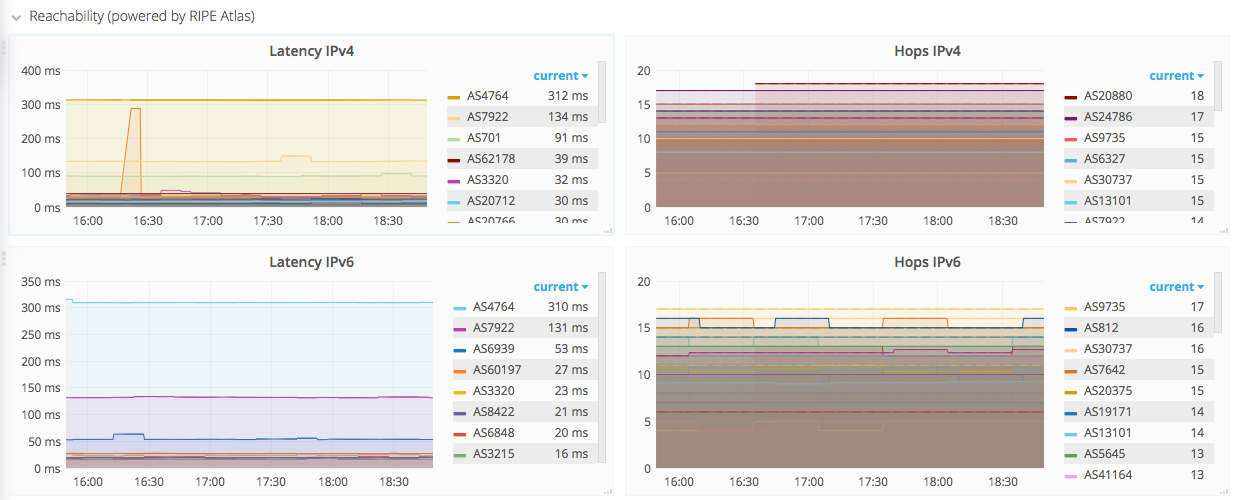
Nous avons un probelème : Neutrinet est trop bien connectée.
Toutes nos probes passent par un lien de peering, et plus aucune ne passe par un lien de transit.
Dans le schéma suivant, une case verte = nœud d'échange. Mais certains IX ne sont pas bien reconnu, donc on ne voit pas toujours le lien dans le nœud d'échange.
Hetzner: NL-IX FirstHeberg: v4 NL-IX, v6 BNIX OVH: BelgiumIX






Problème : on ne peut plus se monitorer depuis notre lien de transit.
En fait, NL-IX donne beaucoup de chemins en Europe.
On pourrait utiliser Atlas du RIPE (on a déjà une ancre) et scheduler des mesures pour récupérer les infos. Chaque schedule coûte en crédit, mais tant qu'on dépasse pas 42000 crédits/h on peut se le permettre (c'est ce que nous rapporte l'ancre par heure). Par exemple, un ping en IPv4 toutes les 5min sur 10 probes coûterait 10800 crédits/j, donc 5% de nos revenus. En rajoutant la V6, on serait à 10% de nos crédits par jour. En faisant toutes les 1min, cela coûterait 40%.
Il faut voir comment récupérer les métriques et les mettre dans Alerte Manager.
https://labs.ripe.net/author/daniel_czerwonk/using-ripe-atlas-measurement-results-in-prometheus/
Peut-être qu'on pourrait se passer de la VM Hetzner pour la placer chez un membre de la fédé.
Quid du ring? Le Ring n'a pas d'API pour récupérer des metriques, mais ils ont une toolbox pour se connecter en ssh, et depuis là, en utilisant ring ping, on peut lancer un ping depuis plusieurs serveurs, et ensuite récupérer les valeurs. Donc ce sera à nous de créer un script pour gérer tout ça.
Tandis qu'Atlas, on fait un schedule et il va générer une URL unique avec le rapport dessus.
TODO: Récupérer les metrics d'Atlas dans Prometheus
TODO: Remplacer la probe Hetzner par une VM d'un membre de la FFDN
Choix chiffrement
Proposition: RAID 1 sur les deux disque de 60G avec chiffrement de tout donc la passphrase se tape au moment du grub. On la déverouille depuis la console serial accessible depuis le ssh du ilo
Si les deux serveurs redémarrent en même temps (coupure électrique…), là il faudra se rendre sur place car on n'a pas encore d'accès au ilo.
Petit aparté électricité : Verixi aimerait changer la responsabilite de l'ATS… un jour. Mais de toute façon, normalement il y a un backup en cas de panne de courant.
On a deux arrivées électriques différentes : une redondée et une pas redondée.
Proposition sur le chiffrement : acceptée à l'unanimité de nous 3 \o/ (dont une abstention)
Hub DC
Carte démagnétisée
Nous avons encore un problème Houston.
Notre carte est démagnétisée, Verixi est déjà au courant.
Placement du matériel
Journée LouiseDC le 11 juin, voir début du compte rendu.
Ca va être une longue journée puisqu'on doit transférer les données qui sont sur les OSD de CEPH. Peut-être commencer le matin et faire la pause de midi pendant que les OSD synchronisent.
Ce serait l'occasion aussi de faire la migration des Proxmox 6 vers Proxmox 7 et debian Bullseye.
En gros, on est bon pour tout réinstaller \o/
Et on va passer en mode debootstrap pour l'installation et choisir les bons paramètres du chiffrement.
Ca veut dire faire ça en très bas niveau, que l'installateur de Debian ne permet pas. C'est encore plus bas niveau que ce qu'on a fait à l'atelier Proxmox avec la mini ISO.
En principe, on aura toujours un serveur up. Il faudra déplacer les VM sur ce serveur. S'il ne plante pas on aura pas trop de problèmes 
On va prier Murphy pour qu'il nous laisse tranquille.
Hub Network
Netbox
https://netbox.dev/ (licence Apache2) https://github.com/netbox-community/netbox
Outil d'inventaire à la fois matériel et réseau.
Ca peut nous servir à plein de trucs  Par exemple:
Par exemple:
- IP et vlan
- gestion des zones reverse dns
- invertaire matériel
- inventaire des VMs
- inventaire des circuits réseau
- inventaire ansible
Tharyrok est trop limité au niveau de l'IPAM qui se trouve dans le wiki .
Mais : pour Netbox il faut un compte et utiliser keycloak
Netbox a été créé par Digital Ocean pour eux-mêmes d'abord puis ils l'ont mis à disposition.
Si on l'adopte, ce serait bien de faire tout ce qu'on a listé dans l'exemple ci-dessus.
Ça a l'air très puissant comme outil, parce qu'on peut facilement passer 10h à parcourir tout l'outil. Mais une fois en place, ça peut être très utile.
Pour l'instant c'est bloquant pour la gestion des IPs et VLAN ainsi que les reverse DNS.
Et du coup la gestion des reverse DNS se fera via Netbox, soit via l'interface graphique, soit en tapant sur l'API.
Il y a aussi moyen d'avoir une partie publique et une partie privée, à voir ce qu'on condidère comme donnée sensible.
Ca pourrait aussi permettre de générer des configs, par exemple, en entrant les VLANs, générer la configuration des switchs (même nos vieux switchs).
Ça ne gère pas l'inventaire des stocks de café…
TODO: Neutriton démo Netbox
TODO: Tharyrok installe Netbox pour avoir un IPAM à jour
Peering Manager
Pareil que Netbox mais pour du BGP. Il peut générer la config router, en se basant sur peeringdb.
Ca peut récupérer les peer, envoyer des mails automatiquement lorsque quelqu'un rejoint pour faire une demande de peering, etc.
L'idée ce serait de l'utiliser en mode inventaire, pour avoir une bonne vue des peerings acceptés, refusés (avec les raisons du refus), etc.
Peering Manager peut se coupler à NetBox pour s'auto-provisionner, et réciproquement et vice et versa.
C'est utilisé notamment par DE-CIX et LINX.
TODO: Tharyrok va jouer avec Peering Manager
TODO: Neutriton démo Peering Manager (en même temps que NetBox)
NL-IX
Eh bien voilà… c'est configuré ! \o/
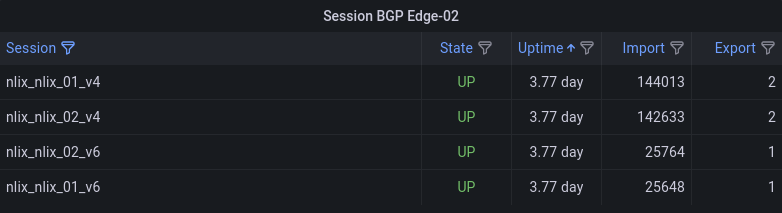
Un dashboard public existe avec les sessions BGP: https://grafana.neutrinet.be/d/s0ZQdGB7k/bgp?orgId=1
Hub Dev
Hub Chez mémé
VPS
TODO: choisir une date pour reinstaller et chiffrer les serveurs
Prochaine réunion
Keycloak 02/07 (à confirmer avec wget) au caldarium
Prochaine réunion infra : 23/07 à 14:00 sur Jitsi & Caldarium
Météo de fin
Moment informel durant lequel on exprime en peu de mots comment, à titre personnel, la réunion a été vécue que ce soit positif ou négatif. Si une ou plusieurs tension est née durant la réunion, il est peut-être nécessaire d'envisager l'une ou l'autre réunion pour y remédier.