Table des matières
2021/05/23 (Neutriton) : Installation des VMs
Présences :
- Celo
- Tharyrok
- HgO
- ~~tierce~~ Il est là mais pas là
- zefredz
- squeak
- niko
Caldarium : https://caldarium.be/fr:contact
Météo
Moment informel durant lequel on exprime en peu de mots comment on se sent et si on a une attente forte pour la réunion.
Ce n'est pas un moment de discussion mais d'expression individuelle et ce n'est pas obligatoire 
Attente(s) forte(s)
Si l'une ou l'autre personne exprime une attente forte, merci de vous en occuper en priorité ou de la noter dans le hub ou dans un point approprié.
Ordre du jour
Installation des VMs
Prendre le temps d’installer des VMs via Ansible.
La journée sera divisée en deux partie : - Le matin un petit rappel théorique + préparation des VMs dans Proxmox - L'après-midi création des playbooks Ansible et installation des services
Pourquoi Ansible ?
Dans Neutrinet, plusieurs niveaux d'intervenants dans l'infra : des gens qui font ça tous les jours, d'autres qui font ça de temps en temps.
Comment garder une documentation de ce qu'on a et comment on l'a ? Ansible est une première réponse parce qu'il nous pousse à décrire l'infrastructure.
Lors d'un Neutriton précédent, on a choisi Ansible (outil de config management)
Le choix s'est porté sur Ansible pour sa facilité d'apprentissage et la documentation qui est riche sur internet. En plus des membres connaissaient déjà donc plus facile d'utiliser cet outil que d'en apprendre un nouveau. Et des playbooks existaient déjà sur le Gitlab de Neutrinet.
On désire aussi avoir un labo pour pouvoir faire des tests, puis le mettre dans l'infrastructure et avoir quelque chose de reproductible.
En résumé, cet outil va rendre visible l'infrastructure sous forme d'instructions, de tâches, qui sont assurées d'avoir toujours le même effet si le playbook est bien fait donc si les instructions sont bien écrite. Ce qui est aussi intéressant c'est qu'on peut faire des tests sur une machine et c'est reproductible sur une autre, on peut donc faire des essais sur son ordinateur, puis dans un environnement de test, puis sur l'infra… à voir le nombre d'étapes. C'est plus fiable que des script bash qui sont parfois obscure.
C'est quoi Ansible ?
C'est un outil créé en python qui va lire des fichiers yaml. Actuellement géré par RedHat. Utilise SSH pour se connecter aux serveurs
Le schéma classique est de lancer un playbook, un ensemble de recettes écrites avant, et Ansible va se connecter en SSH sur le serveur et en fonction de ce qui est écrit dans les playbook, va identifier une différence et lancer les instructions pour que cela correspondent au playbook. Si le playbook est bien fait, lors qu'on le lance une seconde fois, il ne va rien faire.
Quand on va vouloir installer un paquet sur Debian, Ansible va détecter qu'il est déjà installé. S'il est installé, Ansible ne fera rien (tâche ok), sinon il l'installera (tâche modifiée)
Ansible utilise SSH et a souvent besoin des droits root, entre autres pour installer un paquet.
Plusieurs possibilités : - autoriser root de se connecter en ssh - utiliser l'outil sudo, mais s'assurer qu'il n'y a pas besoin de mot de passe pour devenir root
Si on ne lance jamais Ansible, les changements ne seront pas appliqués. Il faut donc lancer manuellement le playbook (depuis sa machine) après l'avoir modifié.
Dans Ansible, il y a aussi une notion d'inventaire. Ca peut-être une fichier, qui va lister la liste des hôtes à contacter (par exemple tous les proxmox, tous les debian, tous les nextcloud…), et, associé à cet inventaire, il y a des variables qui peuvent être appliquées à toutes les machines d'une catégorie ou groupe. Typiquement, le mot de passe de backup va être différent pour chaque machine : on peut le mettre dans une variable dont la valeur sera différente pour chaque host.
Plusieurs niveaux de variables :
- au niveau du playbook
- au niveau des rôles (des variables par défauts qui peuvent être définies et qui peuvent être communes, indépendantes de l'infrastructure sur laquelle on exécute le playbook - par ex. si une autre asso trouve qu'on fait un bon travail :p ils peuvent reprendre ce travail pour avoir des variables par défaut.)
Fichier d'inventaire : il peut contenir des commentaires (par ex. expliquant ce qu'est la machine, ses specs, etc.).
Sur chaque ligne, on a un host auquel on peut ajouter des variables. On peut aussi mettre ces variables dans un fichier séparé.
Catégories et groupes : la même chose pour Ansible. Elles sont à la fin du fichier d'inventaire.
L'inventaire a le nom de toutes les machines → Ansible s'y connectera en SSH donc il faut le domaine. On pourrait mettre l'IP mais c'est moins clair. Par contre peut être utile si on vient de créer la machine et qu'elle n'a qu'une IP.
Playbooks de Neutrinet
Un préalable le nommage : le nom des machines, le lieu (le data center), pour la nouvelle infra, on ajoute le cluster, ici ce sera patata.
Chez Neutrinet, on a choisi de faire un playbook commun à tout qui s'occupe de l'installation de base. Ensuite, on a des playbook spécifiques (pour Nextcloud par exemple). Mais on pourrait changer ça. On verra ça cette après-midi.
Lecture ligne par ligne : ligne 5 hosts: all → tous les hôtes repris dans l'inventaire. Si on mettait Nextcloud à la place de all, ça ne prendra que les machines en dessous de la ligne 46 de l'inventaire → donc la machihe Nextcloud.
Ligne : 8 pre_tasks: indique que c'est une tâche qui va être jouée avant les rôles (d'habitude elles sont après → par ex. un apt update… sinon Ansible le fera avant chaque paquet à installer, si on le fait en amont on optimise)
Ligne 13 : → liste des rôles.
On voit quels rôles sont listé dans le dossier roles. Là, les rôles sont définis.
Pour un rôle, Ansible commence par le fichier Yaml mais va ensutie trouver le fichier tasks pour les tâches, etc… Quand on inclut un rôle, fichier main.yaml, on utilise l'action import tasks et on réfère le nom du fichier.
Ansible lit toujours du haut vers le bas.
Fichier repos.yml on a :
un nom, c'est pas obligatoire, mais c'est une bonne pratique pour comprendre ce qui est en train de se passer, c'est ça qui sera affiché pour chaque étape. Tâche template : par défaut, il va regarder dans le dossier template s'il y a un fichier template.
Template est une action propre à Ansible, documentée ici : https://docs.ansible.com/ansible/latest/collections/ansible/builtin/template_module.html
Les variables : sont entre double brackets {{}}. Une des premières choses faites par Ansible, c'est récupérer les facts. Ceux-ci sont des variables sur notre machines (infos du système, OS, version de l'OS, IP, disques durs, CPU, etc.) Une varialbe ansible_distribution_relaese renvera buster pour une Debian Buster. Si Ansible ne peut remplir la variable, il va renvoyer une erreur.
Ansible : permet de poser des contraintes avec when → idée, si les repos ont changé, on actualise les repos, sinon pas.
Dans 50unattendedupgrades, on a une variable mail_notification, c'est une variable qu'on a créé et qui n'est pas directement dans Ansible. On l'a définie à la fin du fichier. Lorsqu'on précise une variable dans un playbook, ça écrase la variable qui est définie dans le playbook all.
Dans all, on a des variables par défaut dans défaults. Elles seront utilisées pour nos tests en local par exemple, mais une fois en situation elle seront remplacées par des variables plus précises.
On peut mettre le nom complet des actions dans Ansible pour plus de précision. En général le nom du module suffit mais parfois il y a des ambiguités (Ansible le signale en principe).
locale_gen : permet de générer les locales sur un serveur. Ce qui fait que si on se connecte avec une machine qui a une locale, on ne se retrouve pas avec un serveur qui ne la trouve pas. ansible.builtin.package par ex.
Dans loop : on met les trois langues et ensuite on explique comment on définit la variable qui va nous servir. locale ne contiendra qu'un seul élément.
Comment Neutrinet a résolu le problème de lancer sudo sans mot de passe root. On a fait le choix d'accepter qu'une clé SSH était une bon moyen d'identification et d'authentification sans avoir un mot de passe sur le serveur. Donc sur le serveur, nos comptes n'ont même pas de mots de passe, ni pour utiliser sudo. On a modifié le fichier sudoers en conséquence pour autoriser ça.
Pour s'assurer que la syntaxe est correcte, on a aussi fait une commande dans Ansible qui s'assure que la syntaxe est correcte.
Fichier user : → la liste des utilisateurs et leurs clés SSH. → une boucle loop sur les utilisateurs.
notify : si on appelle le nom du handler, il n'exécute le handler que lorsqu'il y a une modification.
Les handler, le mieux est de les exécuter le plus tôt possible.
Matinée
- Rappel des différents concepts liés à Ansible (structure des dossiers, playbook, inventaire, ttasks, etc.)
- Création des VMs dans Proxmox
Midi
- On mange ensemble \o/
- Moments informels pour papoter, se reposer, se balader, etc.
Après-midi
On va se baser sur l'inventaire : https://wiki.neutrinet.be/fr/rapports/2020/12-27
On va faire du ceph S3 : https://wiki.neutrinet.be/fr/rapports/2021/01-23?s[]=s3
Le repo git de Neutrinet : https://git.domainepublic.net/Neutrinet/infra
- Création des playbooks Ansible pour les VMs suivantes :
- Reverse proxy (pour configurer les haproxy)
- PostgreSQL HA (patroni + etcd + postgres)
- Website static (pour y placer les anciens wiki)
- Hedgedoc, Nextcloud ou n'importe quel « gros » service qu'on aimerait installer en premier
- Installation des services
Auto install de debian
On va utiliser un fichier de preseed de debian. On ne rentre pas dans les détails de comment ça fonctionne aujourd'hui. Un exemple se trouve ici : https://gitlab.domainepublic.net/Neutrinet/ketupa/build-images/
On découpe en petits bouts : - langue - timezone - compte root - config de apt - install de paquets spécifiques (openssh, python3) pour ansible - tasksel none → install minimaliste de debian - partitionnement - post-install → autorise connexion ssh
La doc de debian explique bien comment ajouter le fichier de preseed pour une image debian : https://wiki.debian.org/DebianInstaller/Preseed/EditIso
Note : Chez Centos, ils appellent ça un kickstarter :neutral_face:
On a donc installé haproxy-01 et haproxy-02 :) \o/
Création playbook haproxy
- acme-bot
- template acme-bot
- apt install haproxy
- template haproxy
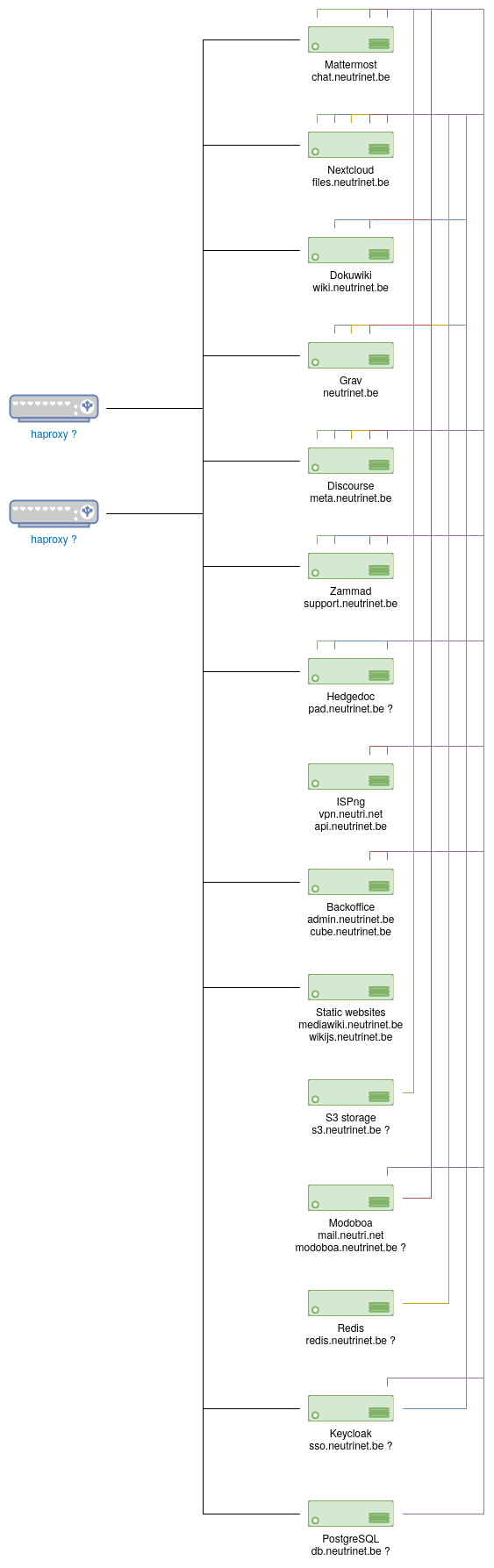
Création de la VM web-static
- Créer une VM depuis l'iso preseed-debian-10-neutrinet
Comment ajouter un utilisateur
- Ajouter la clé SSH dans le repo git
- Ajouter l'utilisateur dans pfsense (User Manager) avec clé ssh
- Ajouter l'utilisateur dans proxmox
- Se connecter via root + mdp dans le password manager, le tout en Linux PAM
- Dans Datacenter > Permissions > Users, ajouter l'utilisateur
- Se connecter en ssh sur 80.67.181.17 (gateway) avec l'option
-D 1080 - Configurer FoxyProxy
- socks5 vers localhost:1080
- modèle d'inclusion: 10.0.11.*
- Se connecter au pfsense: https://10.0.10.61/
- Se connecter au Proxmox: https://10.0.10.11:8006 (nam)
- Choisir Proxmox VE
Prochaine réunion
:warning: Prochain Neutriton : JJ/MM à HH:MM
:warning: Lieu : Mumble et/ou Caldarium ?
Météo de fin
Moment informel durant lequel on exprime en peu de mots comment, à titre personnel, la réunion a été vécue que ce soit positif ou négatif. Si une ou plusieurs tension est née durant la réunion, il est peut-être nécessaire d'envisager l'une ou l'autre réunion pour y remédier.